Support Vector Machines
Classification
Model
High Level Idea of SVMs
Functional Margin
Definition:
Some Observations:
- If $y^{(i)} = 1$, the larger $w^Tx + b$ is, the larger the functional margin will be.
- The value of $\hat \gamma$ is affected by the scale of $w$ and $b$; therefore, it is reasonable to introduce normalization.
Functional Margin for a dataset with $m$ instances:
Geometric Margin
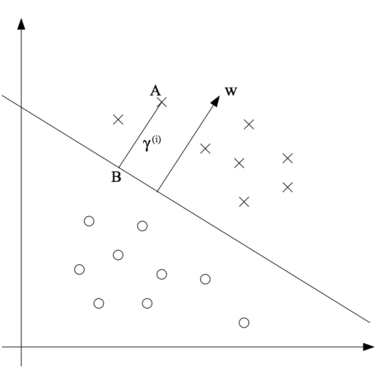
Geometric Margin
(Original Graph: http://cs229.stanford.edu/notes/cs229-notes3.pdf)
Define the geometric margin of ($w$, $b$) with respect to a training example ($x^{(i)}$, $y^{(i)}$):
Geometric Margin for a dataset with $m$ instances:
Training
To train SVM, it is equivalent to find a hyperplane that can achieves the maximum geometric margin
Since "$\Vert w \Vert = 1$" is a non-convex constraint, transform the problem into the following:
Introduce the scaling constraint that the functional margin of $w, b$ with respect to the training set must be 1. That is, $\hat \gamma = 1$. The problem has become a convex quadratic objective with linear constraints and its solution gives use the optimal margin classifier.
The dual problem that used for Kernel tricks
For soft margin classification:
Linear models
- Hard Margin: Strictly enforce that all instances must be off the margin and on the right sides.
- only works for linear separable datasets
- sensitive to outliers
- Soft Margin: Relax the restriction of hart margin model.
- In Scikit-Learn's SVM classes, hyperparameter C is used to control the flexibility. A smaller C leads to a wider margin but more margin violations
from sklearn.pipeline import pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import LinearSVC
svm_clf = Pipeline([
('scaler', StandardScaler()),
('linear_svc', LinearSVC(C=1, loss='hinge')),
])
svm_clf.fit(X_train, Y_train)
Non-linear models
In the dual form optimization problem above, ${\mathbf x^{(i)}}^T \mathbf x^{(j)}$ can be replaced with $K(\mathbf a, \mathbf b)$
- Polynomial Kernel
from sklearn.pipeline import pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
poly_kernel_svm_clf = Pipeline([
('scaler', StandardScaler()),
('poly_svc', SVC(kernel='poly', degree=3, coef0=3, C=5)),
])
poly_kernel_svm_clf.fit(X_train, Y_train)
- Gaussian RBF Kernel
from sklearn.pipeline import pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
rbf_kernel_svm_clf = Pipeline([
('scaler', StandardScaler()),
('rbf_svc', SVC(kernel='rbf', gamma=5, C=0.001)),
])
rbf_kernel_svm_clf.fit(X_train, Y_train)
- Sigmoid
from sklearn.pipeline import pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
sigmoid_kernel_svm_clf = Pipeline([
('scaler', StandardScaler()),
('sigmoid_svc', SVC(kernel='sigmoid')),
])
sigmoid_kernel_svm_clf.fit(X_train, Y_train)
Regression
Model
In an SVM regression problem, a model tries to keep as many points as possible inside a margin $\epsilon$.
Training
The optimization problem for SVM regression is the following:
To allow some points to be outside the margin, the optimization problem becomes:
Code
from sklearn import LinearSVR
svm_reg = LinearSVR(epsilon=1.5)
svm_reg.fit(X_train, Y_train)
from sklearn import SVR
svm_reg = SVR(kernel='poly', degree=2, c=100, epsilon=0.5)
svm_reg.fit(X_train, Y_train)